I’m sure it depends on the coding background that you have, but here is a real-world problem from my experience (though the experience was thankfully years ago, so some details are a bit hazy). Much of this description would not be necessary for anyone who had worked on a similar system at that time.
Background
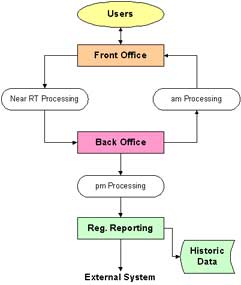 You are on a customer site, working on some minor mods to your companies trading system.
You are on a customer site, working on some minor mods to your companies trading system.
The trading system comes in two parts, Front Office (FO / Trading) which provides all the UI elements, real-time, etc, and a Back Office (BO / Settlements) which maintains the books etc. The FO sends trades to the BO in near-real-time. When the BO loads a trade, it carries out several operations, e.g. creating a main Trade record but also Child records for splits of stock blah blah blah. At the end of the trading day, the BO sends details of those trades to a regulatory authority (via a dedicated terminal system on-site), and then overnight also sends updates back to the FO for book totals etc. You are a member of the BO / Settlements team.
Problem
A hardware engineer for the customer comes in because one of the disks is reporting faulty, so the database has been suffering from extremely poor performance. Hey, it’s a fault-tolerant system, and he’s being paid by the hour, so the non-technical customer and engineer agree to do a hotswap without backing up first. Following the regulatory reporting element of the BO system, at about 6-7pm, they go ahead. Unfortunately, no-one switched on the setting to allow hot-swaps. Ergo, the RAID array is now non-functioning.
What do you do?
‘Specification’ / Answers to Questions:
- You can boot the Unix box, just, but some general filesystems need to be restored, and the BO database is trashed. Your last backup is from Friday night (today is Monday);
- The FO must be up and running by tomorrow 8am else £thousands will be lost in revenue and fines;
- The BO must be available to report the trades that happen tomorrow, by the early evening;
- No work went on at the weekend;
- The FO does not require a database. It does need some external data-feeds, it does not have to have updated files from the BO;
- The BO database can only be restored from Friday night. All the on-system files referring to trades sent from the FO to the BO during Monday have been destroyed with the disks;
- You can get away with the BO overnights not being run for a night (maybe two, I don’t recall). But due to other reporting, if it is not back quickly more £££ fines!
- You must recover the missing trades information for the trades inserted into the BO during Monday day. Assume put-them-out-of-business fines if you don’t;
- You have access to: The non-techie client representative. A Unix_SA is on-site and is available to assist. There are no DBA’s on-site. Your management, and your own DBA, FO staff by phone. DBA can probably dial-in. Other staff can not be on-site til late the following morning.
There are undoubtedly some points not answered above. Assume that there were answers for them (the backups were available to us, or could be delivered within a couple of hours, whatever). A key point hinted at above, but not clarified (because it is a big clue to give) is that the only place the Trade data now resides is on that dedicated terminal system, and its in a flat file in a different format to anything else (but the data can be converted to being usable).
What We Did
Yes, it was me, plus a Unix SysAdmin on-site. Yuk (to the situation, not the Unix-SA). The kind-of problem where you know for a fact that you had no part in the cause, but it was ‘your’ system that was screwed up. Who else was going to do it?
What we did went something like this:
- Unix SA + Annoying engineer starts rebuild of RAID array;
- Unix SA restores the file systems he can, from the Friday backups (we got hold of them somehow, I forget now);
- Unix SA plus myself, in conversation with DBA somehow figure out how to restore the database (possible issues with doing this from a dial-in? I don’t recall);
- All the above takes the whole night. I seem to recall we got the Front Office up in time (we knew it would be from some point in the early hours), but the Back Office took a little longer – it does take hours to rebuild a RAID array, and restore DB’s etc.;
- So, during Tuesday the main focus for me was the BO. We got it running, so it processed the day’s FO trades. A FO team-member arrived, I got some kip at my hotel, Unix SA flies home;
- For some reason that I do not recall, I was working afternoons and through the nights from Tuesday. Probably had something to do with BO mostly being batch processes, still needing some tuning following the disk problems, etc.
- So at this point, we are up-to-date with regulatory reporting for Monday and Tuesday, but still missing Mondays trades from the DB. No money has yet been lost in fines. The FO does not have up-to-date info for book totals etc (from the BO overnights), but this is tolerable as we have told them of this;
- By this stage we have also recovered the trades information, in a flat-file from the Regulatory Reporting terminal. In conjunction with FO staff and others, we decide that the simplest way to get it back into the database is to use the existing method – the ‘Bridge’ between Front Office and Back Office, but bastardised in numerous ways. We agree what those ways need to be… and as I recall, I have to work on some sort of dataload and conversion program to get the flat file up into the DB (temp table) and converted into the appropriate format;
- In truth, I think that we had lost some data, it may have been the time of the trade or something like that, but we probably had to agree some sort of work around (like pick midday for the trade time, or similar). Bear in mind that the original FO data had been transformed probably three times to get to the Regulatory data, and we were trying to transform it ‘back’ so that we could run it through a system as much like the normal load as possible;
- By Wednesday night, we had our data ready to load, with a modified loader. I seem to remember that by this time, we had a DBA on-site, and several other team-members… not to mention the customer’s staff! Without recalling the details of exact time, I do remember that we started the load process, and it crawled. Bish bash bosh, we now had to solve a serious speed issue due to time constraints. A bit of investigation later, and having added an index on one of the load tables, the whole load of, maybe a thousand records, shot through in moments;
For some reason, I have a feeling that everyone else went home or back to the hotel, and I got to watch the overnight batch run through, due to it’s importance. So, by Thursday morning, the FO was back up-to-date, the BO was fully up to date, and the customer was still in business.
Overall, I considered that to be a big success! I have to say, that I feel a great deal of personal accomplishment from this. Sure, at many, many points the result was part of a team effort and it could not have happened otherwise. But, at many of the key times, it was me ‘on the ground’ ‘at the coalface’ doing the dirty. It was the BO system that had been most badly effected by the problem, and I was the BO team member on the spot, fixing it.
What we did Wrong
I do not believe that we (the company I represented) were involved in any way with respect to the disk-swap and the decision to hot-swap the disk without a backup. I suspect that we were told “We are going to hot-swap the disk without a backup, because the array will rebuild itself, and a backup will effect the overnights too much” – and if I had heard that it would probably have made sense to me, especially as it would have been me who had to stay up all night! But it was the decision of the client and their contract engineer.
Of course, what the engineer did wrong is that he did not check that the hot-swapping was actually enabled. Frankly, it still blows my mind that a disk array that is physically designed to allow hot-swapping has a software option to disallow it. Needless to say, I suspect this added to many of the arguments that followed:
As a company, and possibly individually, I think the biggest mistake was a financial one. I / we made the morally correct judgement at the time that here was a big problem, and we were placed to at least try and fix it. So we tried. However, our convenient presence on the spot made it too easy for the client… had we not been there, they would have had to come to us asking for help. Considering that I’d done an eighty-some hour week by the Friday, (and I suspect I had to stay Saturday too, to do the stuff I was there for in the first place) was away from home, etc etc, I did agree with my manager to get some sort of overtime / recompense payment, as did a number of other staff. I understand that when our company tried to bill the client for this time later on, there were all sorts of arguments about it. I believe that the waters were muddied because we were on site at the trailing edge of an installation / upgrade type work… so we were there for specific contractual reasons… but clearly, to me, the work that we actually did for them during those days was of a substantially different nature and came under a different part of the contract, I would hope.
It would therefore have been appropriate, at least the Tuesday morning when the situation was a bit clearer (and hey, the managers were awake then), to specifically state to the client that we felt our efforts were chargeable. In fact, I am pretty sure that I would have done, but having a chat with your own client contact is not the same as your Director talking to their Director to say “You know you are going to be paying for this, right?”
I only mention this as I think that it is important that when a company pulls out all the stops for someone, that there is a reward for the company and the staff! This may be different from developing your own product, say, but it’s crazy to find out that the efforts may have weakened your own company, even if just in a small way. By the way, every time I’ve worked in a support environment there has had to be some sort of recompense for being called at night – whereas as a developer I may have often chosen to work very late for my own reasons (not necessarily rewardable). The two recompense structures are different and probably should be so.
What we did Right
I don’t recall some of the detail, but the fact the customer was back up-and-running with essentially all their data, with no regulatory deadlines having been missed, and no loss of trading suggests that most of what we did was ‘Very Right’ or at least ‘Fit for Purpose’.
Oh, and in the process of it all we found at least one performance problem with the ‘Bridge’ software – though in fairness it was not a problem as long as the transfers were ‘near real time’.
…Only, we had to Break Every Rule in the Book
We were on a client site, so we had no development or test database or code to carefully control our releases. We were working with LIVE data. The sort of problems you face in environments like this are quite different to shrink-wrap software development. For example, you may not have the chance to create a test database to work with… and you may not wish to put ‘copy’ tables to test with into the live database – for a start, your code is probably set up to differentiate Live and Test environments in your office, but not on the client site, and guess what, if you set up a test table you’d have to change the code, or a configuration variable… and what if you get that wrong, or forget to change it back? We were lucky as most of our code was in script form or could be simulated directly in a CLI like Oracle SQL*Plus. In other words, we had the tools we needed on-site. I don’t know what would have happened if we had had to work with C / Pro*C type programs which we probably didn’t have the source or build-tools available (though doubtless, there would have been a way).
You are left with the fact that you need to be pragmatic about all your decisions. Yes, it would be better to run through a complete development cycle, but you can’t do that here, you don’t have time. Much of the code you write will not be used again (you hope), you have to watch it like a hawk, do whatever limited testing you can (“Let’s try it with one record first”) or whatever… because failing is bigger than you too. It’s probably true that at least at one point during these efforts, we probably had to pop into the database to delete a record or two manually. In this case, it may not be an exageration to say that had we not done what we did, the client would have been out of business in days… which means no client, which means… you get the idea. Consequences.
Oh, and it was at time like these, working in live databases at odd times of night that I came up with a way of working that I call Healthy Paranoia. Think of it as being a few notches away from Obsessive Compulsive Disorder, but well away from ‘Blase’:
- ‘Enter’ is not something you press until you’ve re-read what you typed, and thought about it again!
What an intense experience! How did you keep your nerve / stay calm?